*CTF 2022
Last updated on January 27, 2024 am
NaCl Jump
NaCl
利用字符串可以快速的定位到关键函数
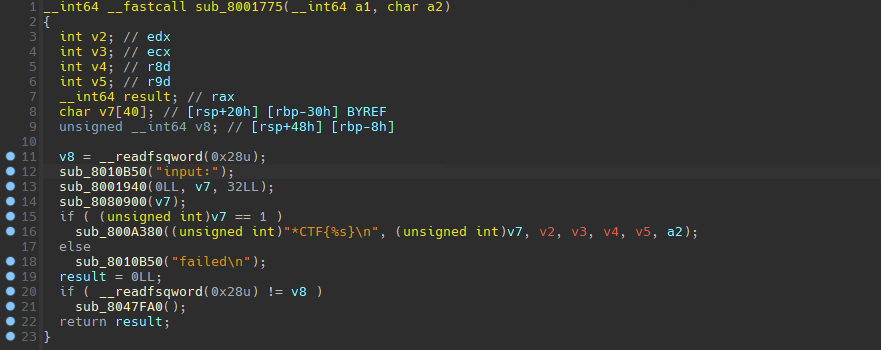
可以发现关键是函数`sub_8080900,跟进该函数
在这函数里面,发现了大量的jmp块
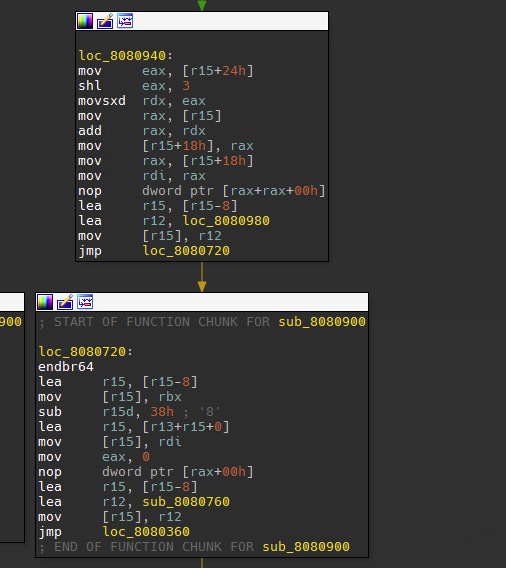
也就是形如lea lea mov jmp的组合
同样还有大量的jmp rdi
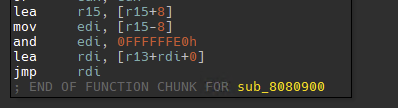
经过调试可以发现,这里的lea lea mov jmp充当了call指令,lea mov and lea jmp充当了retn指令,实际上就是把r15当作rsp来使用。这样就使得函数块割裂,导致IDA识别不准
在由 Microsoft Visual C++ 编译器生成的代码中,经常可以找到函数块
.
编译器移动不常执行的代码段,用以将经常执行的代码段“挤入”不大可能被换出的内存页,由此便产生了函数块
.
如果一个函数以这种方式被分割,IDA 会通过跟踪指向每个块的跳转,尝试定位所有相关的块
.
多数情况下,IDA 都能找到所有这些块,并在函数的头部列出每一个块.
有时候,IDA 可能无法确定与函数关联的每一个块,或者函数可能被错误地识别成函数块,而非函数本身
.
在这种情况下,需要创建自己的函数块,或删除现有的函数块
.
在反汇编代码清单中,函数块就叫做函数块;在 IDA 的菜单系统中,函数块叫做函数尾(function tail)
.
要删除现有的函数块,将光标放在要删除的块中的任何一行上,然后选择 Edit -> Functions -> Remove Function Tail
.
在初次将文件加载到 IDA 时,取消选择 Create function tails 加载器选项,IDA 将不创建函数块
.
如果禁用了函数尾,已经包含函数尾的函数将包含指向函数边界以外区域的跳转,IDA 会在反汇编代码清单左侧的箭头窗口中用红线和箭头突出显示这些跳转
基于此,可以等价的patch这两组指令,使用IDApython会相当方便。这里还要注意需要将Align块也要nop填充
1 | |
patch完后的汇编大概长这样子
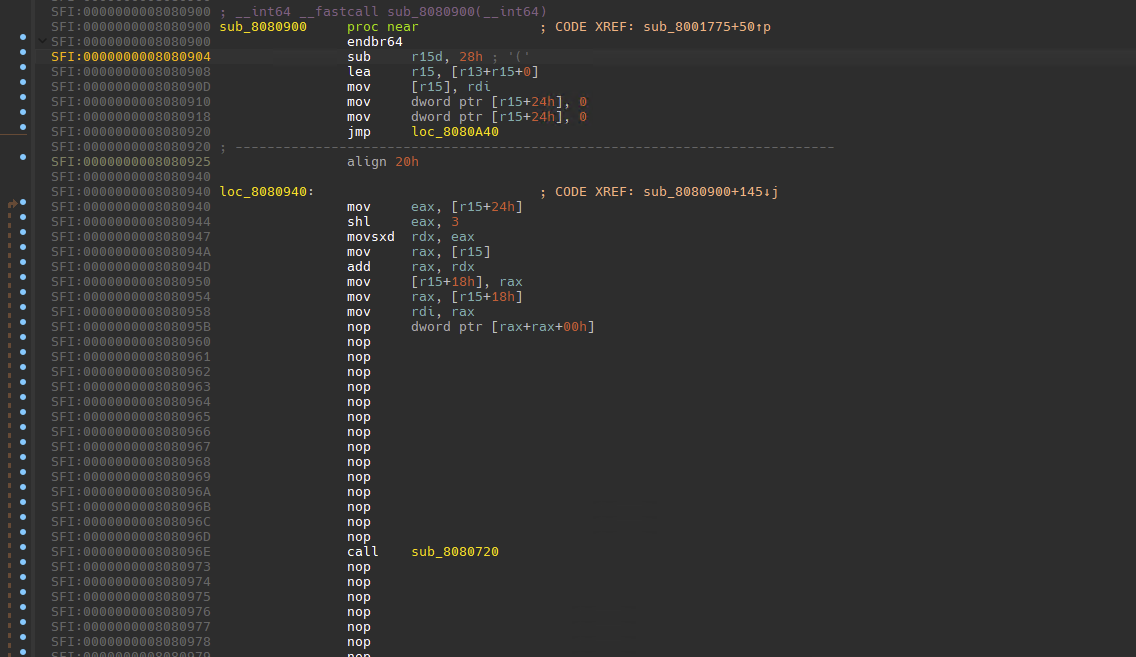
还需要注意的地方是,IDA可能会错误识别函数的边界,需要记住只有retn才是函数的结束,在retn的地方按e标记为函数结束。还有其他应该识别为函数的,比如call sub_xxxx,但是相应地址可能只是loc_xxxx,那就要按p重新分析一下为函数;函数体内不应该存在的sub_xxxx,则需要先按u转为未定义,再按c转为代码。
最后的反汇编应该是这样子
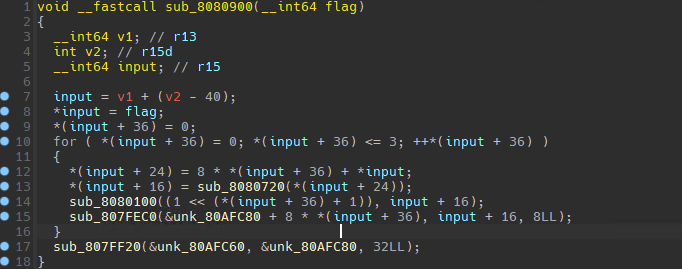
简单分析一下,*(input+36)作为一个索引,将输入分为4个部分,而在之前的函数输入中我们可以得知flag应该是32位,那么这里就是8字节一组的加密,结合for循环的第一句,也验证了这个猜想。
跟入sub_8080720
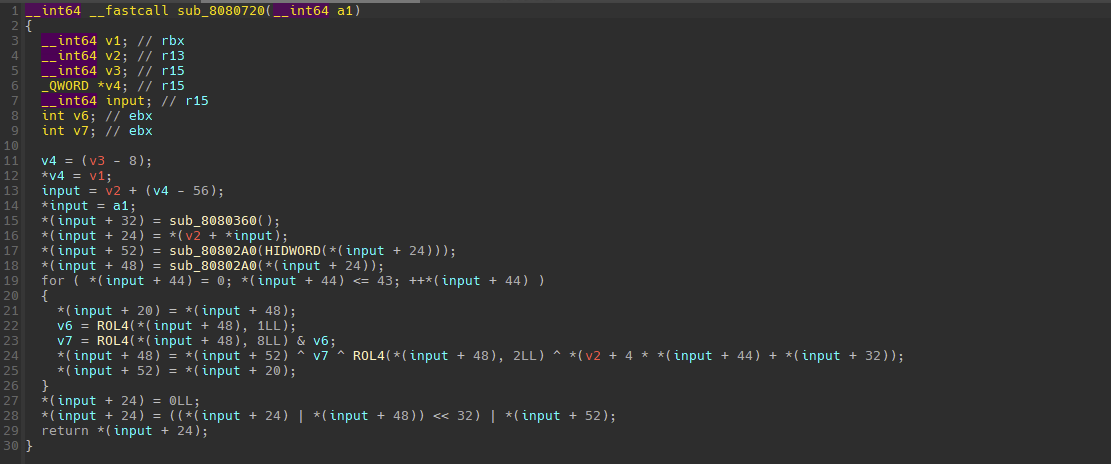
这里面sub_8080360是在做数据准备,与输入无关。
经过调试可以将这段加密等价转为如下python代码
1 | |
这里的v1,v2代表了8字节flag的低4字节和高4字节,table则是由函数sub_8080360得到
经过sub_8080720后,则是进入sub_8080100,这是个很明显的TEA算法
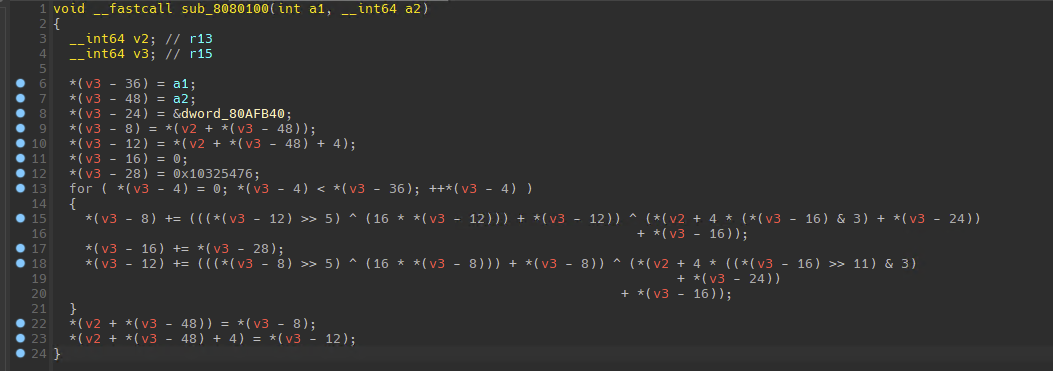
唯一需要注意的是循环轮次与之前的索引有关
现在可以得到完整的加密脚本
1 | |
据此写出逆运算
1 | |
Jump
考点就是setjmp()和longjmp()的配合,这两个函数可以在函数间实现类似goto的跳跃。
简单说就是setjmp会设置一个缓存点,需要一个jmp_buf参数来保存上下文信息,并且返回0零值
longjmp需要一个jmp_buf参数来知晓要去哪个缓存点,还需要一个val参数来告诉要返回什么值。这里要注意的是longjmp函数不返回,而是直接从setjmp返回,返回值就是val
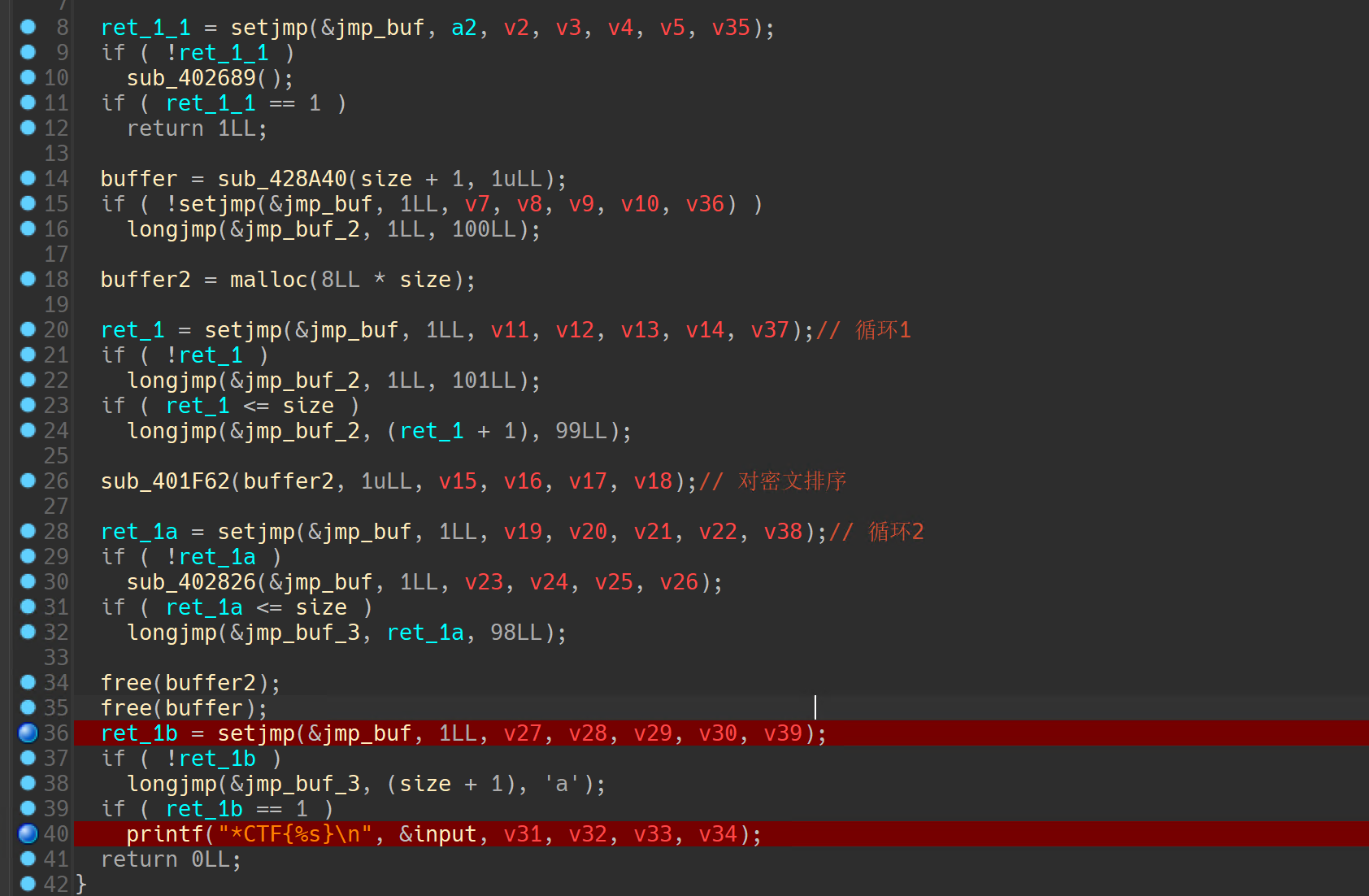
整体的逻辑都比较简单,这里还用setjmp和longjmp做了循环操作。
通过调试可以知道输入0x22个字符,然后每次循环左移1位得到二维数组给buffer2,比如输入985236147adgjlqwesxzcvbnmfuiopvx,就会得到
1 | |
这里的\x02和\x03是程序加的。
然后函数sub_401F62则根据这个二维数组的第一列进行排序,得到
1 | |
再以这个二维数组的最后一列为密文。
那么恢复也比较简单,因为每一行首尾两个一定是相连的
1 | |
cipher就是排序后的最后一列,而sort_ed就是将cipher再进行排序,因为cipher包含了所有flag,那么就得到每一行的第一列。再只要一一对应即可。